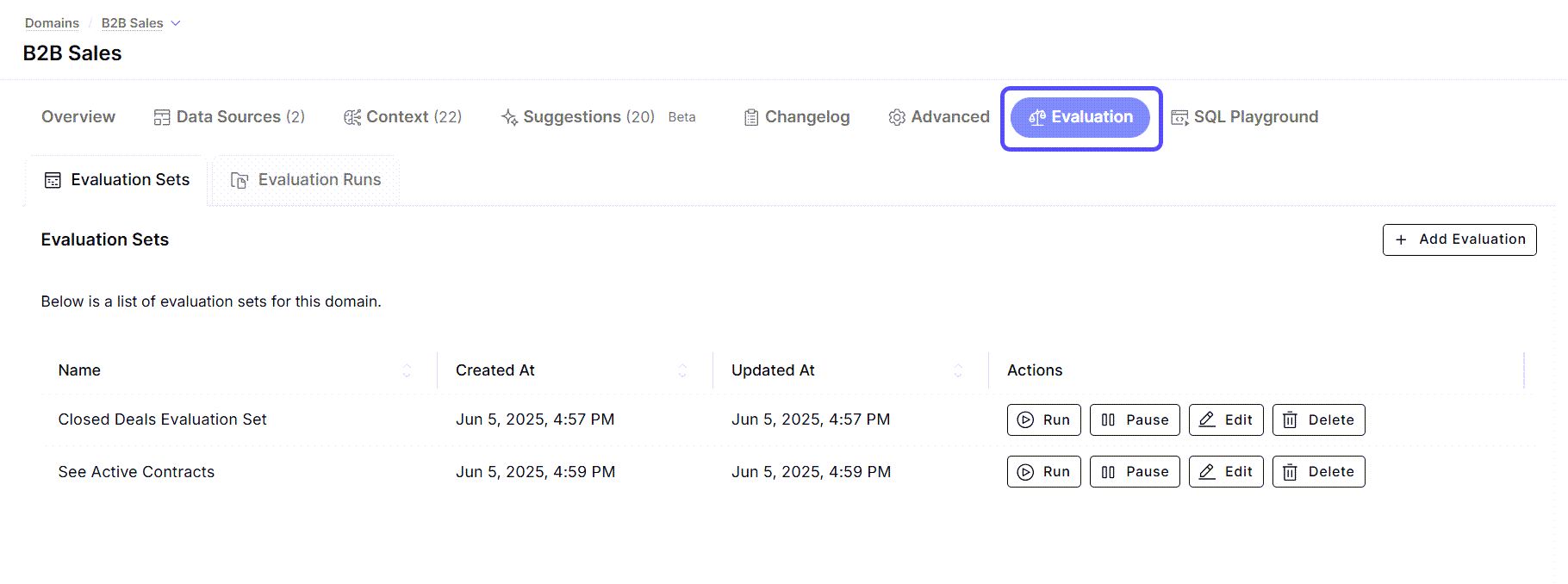
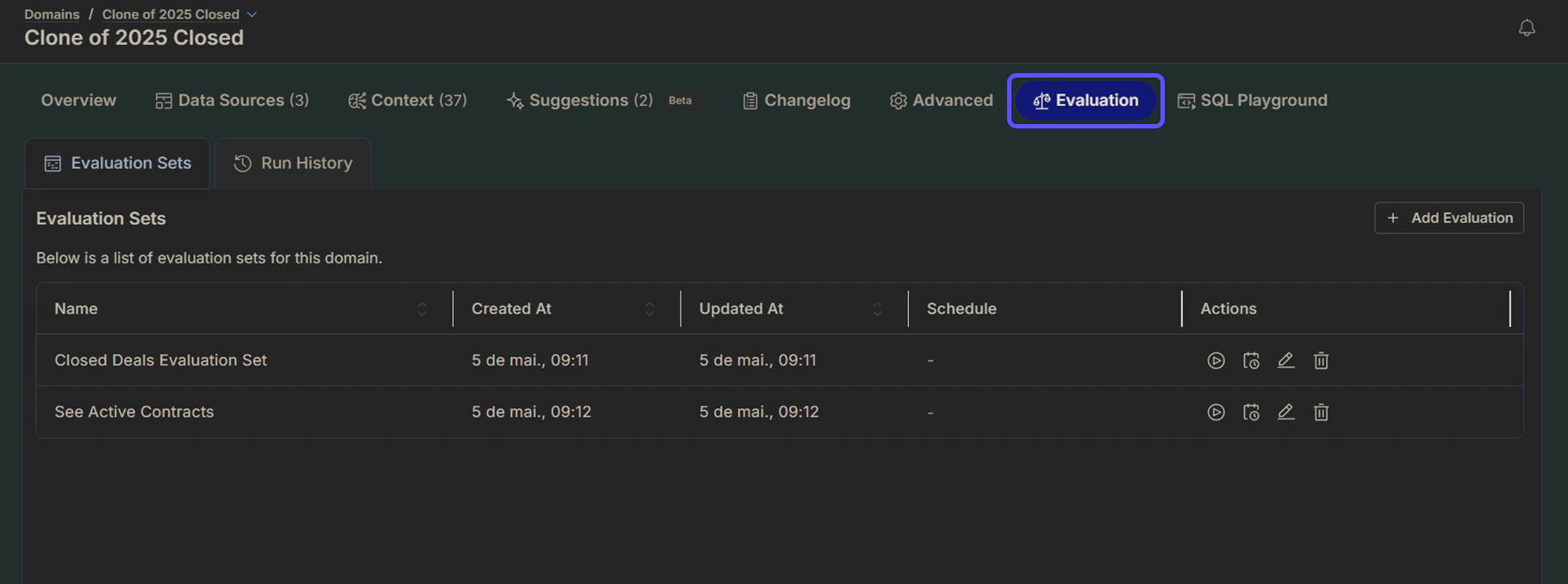
Evaluation Sets
Create and manage collections of prompts for evaluating AI behavior. Add a new evaluation set by providing a name and a JSON definition containing prompts, optionally including expected SQL. Existing evaluation sets are listed in this view, allowing you to review and manage them over time.Evaluation Runs
Find a list of completed evaluation runs and their results. This view allows you to review past executions, compare outcomes, and track how AI performance changes over time.To learn how to create an Evaluation Set, understand indicators, and review results, consult the related article Use Evaluation Sets and Runs.